
숭실대학교 지능형로봇연구소(I³RC)
2010년 연구실적 및 이전가능 기술 소개①
「I³RC 2010년도 기술이전 Workshop」에서 2010년 연구실적 및 이전가능 기술이 발표됐다. 이번 워크샵에서 소개된 참여교수들의 보유기술을 △HRI 기술 △로봇제어기술 △응용기술 △소프트웨어 연동기술로 나누어 일부분만 본지에서 소개한다.
HRI 기술
|
Adaboost와 신경망 조합을 이용한 표정인식 |
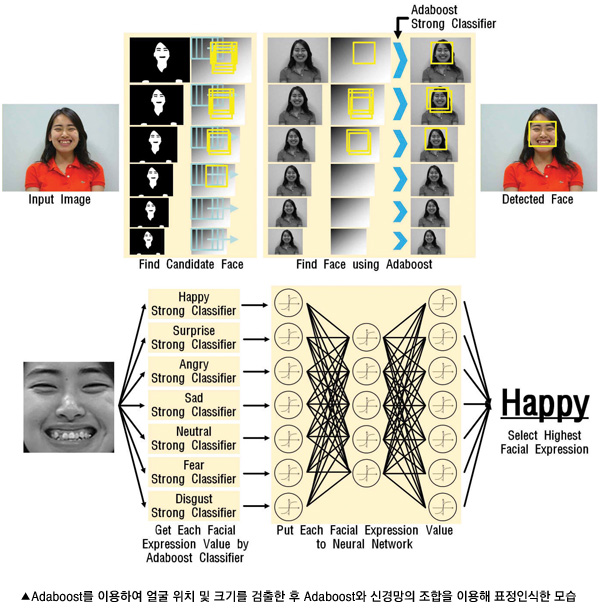
[기술내용]
실시간의 빠른 속도와 높은 정확도를 가지나 출력 값의 기복이 심한 Adaboost 알고리즘과 범용성을 가지나 비교적 느린 신경망 알고리즘을 서로 보완할 수 있는 조합을 이용한 표정인식 기술이다.
각 표정별로 학습된 Adaboost 강분류기 출력을 신경망에 입력하여 모든 표정의 경향을 살펴봄으로써 높은 정확도의 표정인식 시스템을 구현한다.
[응용분야]
토이로봇, 가정용 로봇, 스마트폰 등의 인터페이스 요소로 이용가능하고, 로봇과 사람 간의 감정을 기반한 커뮤니케이션에 활용 가능하며, 디지털 카메라에 응용하여 각 표정을 지을 때 사진 찍는 기술로써 이용할 수 있다.
|
템플릿 매칭 기반의 포즈인식을 통한 다사용성 사용자 중심 인터페이스 |

[기술내용]
포즈 인식은 키보드나 마우스 같은 입력장치 없이 사용자가 직접 컴퓨터와 상호작용할 수 있게 도와주는 방법론 중의 하나이며, 사람의 행동으로 로봇을 제어하는 휴먼-로봇 인터페이스나 실제 행동으로 캐릭터를 조작하여 게임을 즐길 수 있는 인터렉티브(Interactive) 게임 등 다양한 응용 프로그램에서 활용될 수 있다.
포즈 인식은 크게 센서기반과 비전기반 두 가지 방법으로 분류된다. 센서기반방법은 비전기반의 방법보다 배경에 대한 제약 없이 정확하게 포즈를 인식할 수 있는 장점을 가지고 있다. 하지만 센서기반의 방법은 데이터를 얻기 위해 불편한 장비나 센서를 사용자의 몸에 부착해야 하며, 컴퓨터와 센서장비들을 연결하는 선들로 인해 사용자의 움직임이 자연스럽지 못한 단점을 가지고 있다.
따라서 본 기술은 어떠한 연결이나 불편한 장비 없이 사람의 포즈를 인식할 수 있는 비전기반의 포즈 인식 방법에 초점을 맞췄다.
본 시스템은 사용자의 입력을 기반으로 입력 영상으로부터 에지를 추출하고 거리변환함수를 통해 포즈 인식에 대한 전처리를 수행한다. 그리고 템플릿 정보를 결합하여 자동으로 포즈 인식을 수행한다.
[응용분야]
국내외에서도 학계와 연구소를 중심으로 연구가 진행 중이며 사용자 편의의 인터페이스 제공을 위한 포즈인식에 대한 요구가 점차 증대되고 있다.
포즈인식의 산업체 응용분야로는 유비쿼터스 환경에서의 포즈인식을 통한 기기제어, 로봇 제어, 비디오 감시 시스템, 행위 예술을 통한 무대 연출, 교육용 엔터테인먼트 산업 등으로 전체 혹은 부분적인 기술이전도 가능할 것으로 보인다.
|
제스처 인식 및 로봇 제어 기술 |

[기술내용]
카메라 영상의 손 제스처 인식(수화 단어, 베이비 싸인 등)과 임의의 색상을 설정하기 위한 색상 조정 모듈을 포함하고, 손 제스처 그룹화 및 그룹별 멀티 인식 모듈과 손 제스처의 시작과 끝 구분을 인식한다. 인식된 손 제스처 명령에 따라 로봇을 제어하고, 교육 프로그램에서 칭찬, 격려 등 로봇 동작을 표현한다.
또한 웹 브라우저 화면과 카메라 영상, 로봇 동작이 연동되고, 웹 브라우저 제어 및 브라우저 UI에 따른 다양한 반응과 웹 브라우저 내용 소개, 인사 등 다양한 동작을 구현할 수 있다.
[응용분야]
제스처를 이용한 베이비 싸인 교육 시스템, 수화 교육 시스템 등 교육 시스템에서 응용할 수 있고, 제스처를 이용한 로봇 제어 시스템과 원격 조종, 가전 기기 제어 등에도 사용될 수 있다.
|
오디오 및 비디오 정보를 이용한 시공간 음성 구간 검출 방법 및 장치 |
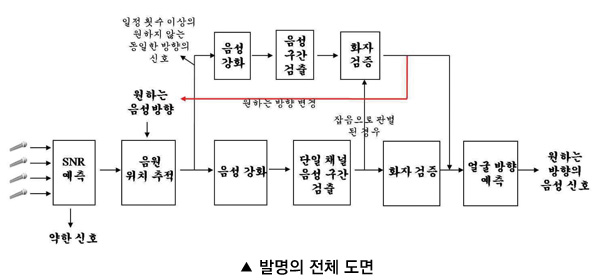
[기술내용]
로봇이나 홈오토메이션과 같은 시스템은 항상 동작하는 도중에 입력되는 신호를 분석하여 사람이 지시하는 행동을 하여야 한다. 이를 위해서는 마이크로폰에 연속적으로 입력되는 신호 중에 사람의 목소리가 있는지 알아내야 화자인식이나 음성인식을 할 수 있다.
이것을 위해서 시스템은 원하는 곳에서 발생한 음성만을 추출해야 하는데, 다른 지점에서 발생하는 원하지 않는 음성 또는 잡음(음성 포함)이 동시에 입력되면 기존 음성 구간 검출 알고리즘들은 매우 낮은 성능을 보인다. 또한, 사용자가 원하는 위치에서 발화하지만 시스템이 아닌 다른 곳을 보며 말을 한다면 이 역시 시스템에서 화자인식이나 음성인식을 수행할 필요가 없는 음성이 된다.
따라서 시스템에서 지정한 위치에서 발생하는 음성 구간만을 검출하고 동시에 화자의 얼굴 방향까지 고려하여 음성 구간 검출 성능을 높이는 기술을 발명하게 됐다.
시스템이 원하는 음성이 발생하는 지점을 미리 알거나, 음원 위치 추적 기법을 통해 신호의 발생위치를 알고 있다고 가정한다. 지정된 방향에서 발생한 잡음을 무시하고 그 곳에서 발생한 음성만을 찾는다. 마이크로폰에 동시에 입력되는 음성과 잡음에 대하여 음성의 구간을 검출하기 위해서는 단일 마이크로폰 보다 마이크로폰 배열을 이용하는 것이 음원의 위치를 탐색할 수 있기 때문에 활용할 수 있는 정보가 많아 유리하다. 이를 해결하기 위한 알고리즘은 6단계로 나눌 수 있다.
우선, 신호의 세기를 이용하여 일정 SNR(Signal-to-Noise Ratio) 이상의 신호에 대해 음성 구간 탐색을 시작한다. 일정 SNR 이상의 마이크로폰 배열에 입력된 신호를 이용하여 음원의 위치를 추적한다. 이 단계에서는 원하지 않은 방향의 신호(음성을 포함한 잡음)를 제거한다. 찾은 음원의 위치와 미리 알고 있던 원하는 신호의 위치를 비교하여 잡음으로 판단하거나 다음 단계로 이동한다. 세 번째 단계는 음성강화 단계로 음성을 강화하고 잡음을 제거한다. 강화된 음성을 기존의 단일 마이크로폰 기반의 음성 구간 검출 기법에 적용한다. 음성의 구간을 정하면 이 신호가 등록된 사용자의 음성인지 화자 검증을 수행한다.
화자 검증 단계에서 등록된 사용자의 신호이면 최종적으로 입력된 비디오 신호에서 얼굴을 검출해 그 얼굴의 방향을 예측하여 시스템 방향을 바라보고 있으면 비로소 최종 음성 구간으로 인식한다.
만약 2단계인 음원위치 추적에서 일정 방향으로의 오류가 연속적으로 발생한다면 시스템은 그 방향에서 화자의 신호가 발생할 가능성을 위해 그 방향에 대해서 음성을 강화하고 음성인지 아닌지 확인한다. 이 신호가 시스템이 원하는 화자라고 밝혀지면 시스템은 처음에 원하는 방향이라고 정하였던 방향을 현재의 방향으로 변경한다. 즉, 화자가 이동하는 경우 추적할 수 있게 된다.
[응용분야]
여러 개의 마이크로폰을 사용하는 음성을 이용한 어플리케이션에서 사용 가능하다.






