
사진. 한국연구재단
한국연구재단은 서울대학교 이재진 교수 연구팀이 영어 기반 언어 모델 라마를 개량해 한국어에 특화된 언어 모델 Llama-Thunder-LLM과 한국어 전용 토크나이저 Thunder-Tok, 한국어 LLM의 성능을 객관적으로 평가할 수 있는 Thunder-LLM 한국어 벤치마크를 개발했다고 밝혔다. 이를 통해 개발 과정 또한 상세히 기술해 누구나 후속 및 재현 연구에 활용할 수 있는 기반을 마련한 것으로 보인다.
연구의 필요성
현재 전 세계적으로 각광받고 있는 거대 언어 모델(LLM)은 대부분 영어를 중심으로 개발돼 있어, 한국어와 같은 비영어권 언어에 대한 성능이 상대적으로 떨어지는 상황이며, 국내에서 개발된 LLM도 한국어의 특성을 이용해 학습 및 추론 효율을 높이는 경우는 거의 전무한 상태이다.
한국어 LLM의 성능을 객관적으로 평가할 수 있는 벤치마크 데이터셋도 매우 부족한 상황으로, 신뢰할 수 있는 평가 기준 마련이 시급했다.
연구내용
서울대 이재진 교수 연구팀은 비용과 자원을 최소화하면서 우수한 성능의 한국어 거대 언어 모델 개발이 가능하도록 기존 영어기반 언어 모델(Llama)을 기반으로 한국어에 특화된 언어 모델인 Llama-Thunder-LLM을 개발했다. 우선, 3TB 크기의 한국어 웹 데이터를 수집하고, 이를 규칙 기반 전처리, GPU 기반의 효율적인 중복 제거, 모델 기반의 데이터 필터링 과정을 거쳐 정제했다. 이후 영어 기반인 Llama3.1-8B 모델을 토대로, 영어 성능은 떨어지지 않으면서도 한국어 성능을 향상시키기 위해 102B 토큰의 한국어와 영어 데이터를 1:1 비율로 학습했다.
또한, 공개된 한국어와 영어 SFT(Supervised Fine-Tuning) 데이터셋을 수집해 미세 조정을 했으며, DPO(Direct Performance Optimization) 학습을 위해 언어 모델로부터 생성한 응답을 기반으로 정답 응답과 오답 응답을 포함하는 선호 학습 데이터셋을 구축했다. 이를 통해 영어와 한국어에 특화된 이중 언어(bi-lingual) 모델을 개발했다.
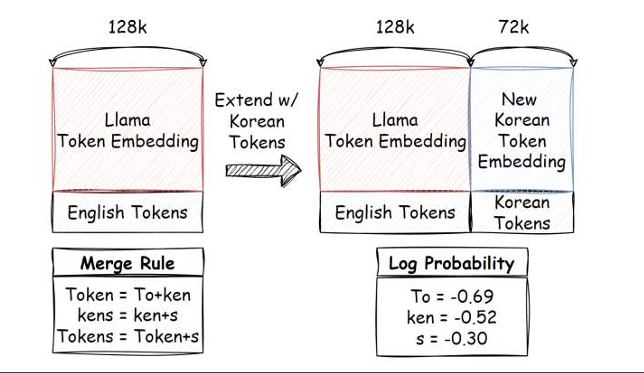
연구팀은 한국어의 언어적 특성에 맞는 토크나이저인 Thunder-Tok을 개발했다. Thunder-Tok은 형태소 기반 전처리와 언어적 특성을 반영한 기법을 개발해 기존 Llama 토크나이저 대비 44% 적은 토큰 수로 같은 한국어 문서를 표현할 수 있게 했고, 이를 통해 추론 속도를 획기적으로 향상시켰다. Thunder-Tok은 Llama-Thunder-LLM의 한국어 토큰 표현력을 높이는 데 활용됐다. 기존 Llama 모델의 영어 성능을 유지하기 위해 영어 토큰의 임베딩은 그대로 보존하고, 새로 추가된 한국어 토큰의 임베딩은 기존 임베딩 벡터들의 평균값으로 초기화하는 방식을 사용했다.
영어로 제작된 대표적인 벤치마크 데이터셋(ARC, GSM8K, EQ-Bench, WinoGrande, IFEval)을 기계 번역 후 도메인 전문가가 직접 교정 및 현지화를 진행한 한국어 평가 데이터셋을 제작해, 한국어 언어 모델을 객관적이고 신뢰성 있게 평가할 수 있는 체계를 마련했다. 또한, 문학적 문맥 이해 능력을 평가하기 위한 Ko-LAMBADA 데이터셋은 단순 번역으로 자연스러운 문장 구성이 어렵고, 영어와 한국어 간 언어 구조 차이로 인해 영어 문장 마지막 단어를 예측하는 기존 방식의 평가가 적절하지 않아, 한국어 문장 내 중요한 명사를 예측하는 방식으로 직접 새롭게 설계해 제작했다. 이에 더해 기존의 한국어 언어 모델 평가 데이터셋 중 그 품질이 뛰어난 것을 선별해 최종 평가 데이터셋인 Thunder-LLM 한국어 벤치마크를 구축했다.
연구성과/기대효과
이번 연구는 막대한 자원과 비용 없이도 기존 공개된 영어 모델을 효율적으로 한국어에 맞게 개량해, 대학이나 중소 연구기관, 기업 등 다양한 주체가 손쉽게 한국어 LLM을 개발하고 활용할 수 있는 기술적 기반을 제시했다는 데 큰 의미가 있다.
개발된 Llama-Thunder-LLM 모델과 Thunder-Tok 토크나이저, Thunder-LLM 한국어 벤치마크를 모두 공개함으로써 누구나 한국어 특화 인공지능 모델을 개발하고 평가할 수 있는 생태계를 조성했다. 이를 통해 대학이나 중소기업도 챗봇, 자동 요약, 번역 서비스 등 다양한 한국어 AI 응용 프로그램을 손쉽게 개발할 수 있어, 인공지능 연구 활성화 및 AI 기술 자립에 기여할 것으로 기대된다.
또한 Thunder-Tok 토크나이저의 한국어에 특화된 효율성으로 인해 추론 비용을 획기적으로 절감할 수 있으며, Thunder-LLM 한국어 벤치마크는 한국어 LLM 성능 평가의 표준화 및 신뢰성 확보에 기여할 것으로 예상돼, 향후 다양한 한국어 모델 간의 공정한 비교와 평가가 가능해질 것으로 기대된다.










